Hi there! 👋,
I had a wonderful time working at Google Summer of Code 2019 this summer.
Here, I would like to give share some of my work done. I will giving a talk on the NLP packages I worked on, at the JuliaCon 2020 Conference.
Check out my project page at Google’s GSoC website
![]()
Acknowledgement
I would like to thank the Google team for giving me this fantastic opportunity to work with the latest research for Deep Learning and Natural Language Processing. I would also like to thank my mentor Dr. Lyndon White, Mr. Avik Sengupta and fellow student GSoCer - Manjunath Bhat.
Summary of work done
-
Deep Learning based neural sequence labelling models.
-
High speed word tokenizers in WordTokenizers package.
-
A julia package for text analysis.
-
A bunch of corpus loaders.
Following I discuss about some of the works.
Ner and Pos Taggers
My project was on Practical Deep Learning models for sequence labelling tasks of Named Entity Recognition and Part of Speech that generalizes well and is fast enough to be used in practice.
Speed and performance comparison against other models.
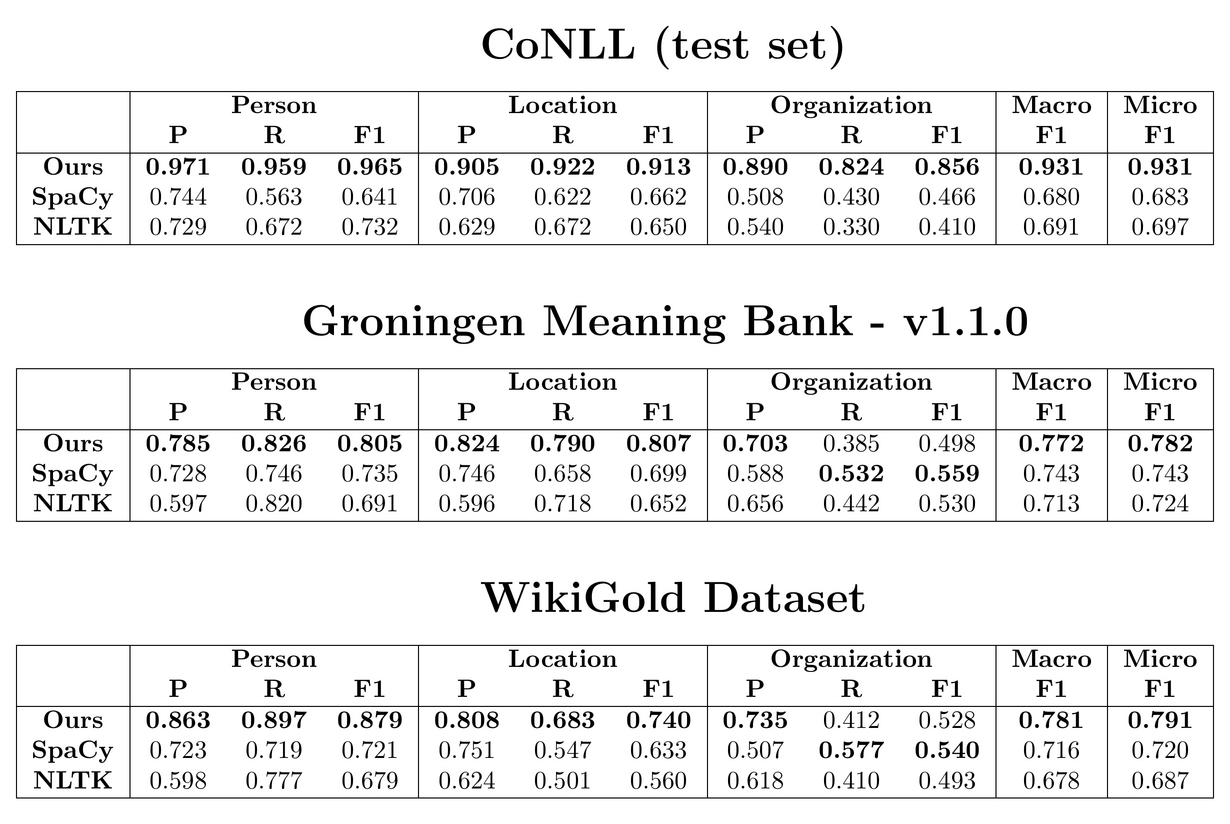
We have open sourced the code and developed an API based on the smaller model, making pretrained NER and POS models accessible in just two lines:
>>> ner = NERTagger()
>>> ner("Some sentence")
similary for POS. The POS tagger performs 0.902 F1 on CoNLL-2003.
Word Tokenizers
I also worked on a novel regex free approach for high-speed WordTokenizers package providing with statistical and (custom) rule-based tokenizers for multiple languages.
Following is a performance analysis comparing the Tokenizers of Spacy, NLTK with our Tokenizers.
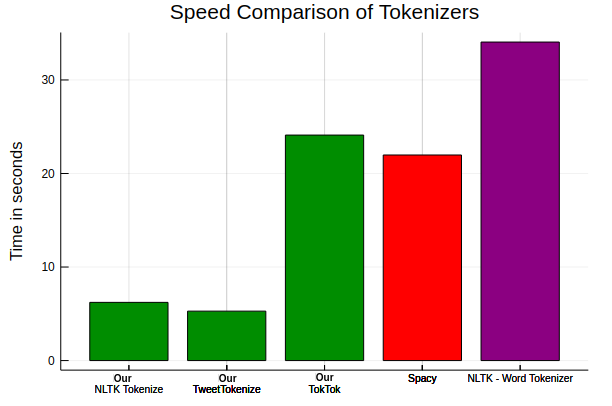
This work has been published at the Journal of Open Source Software.